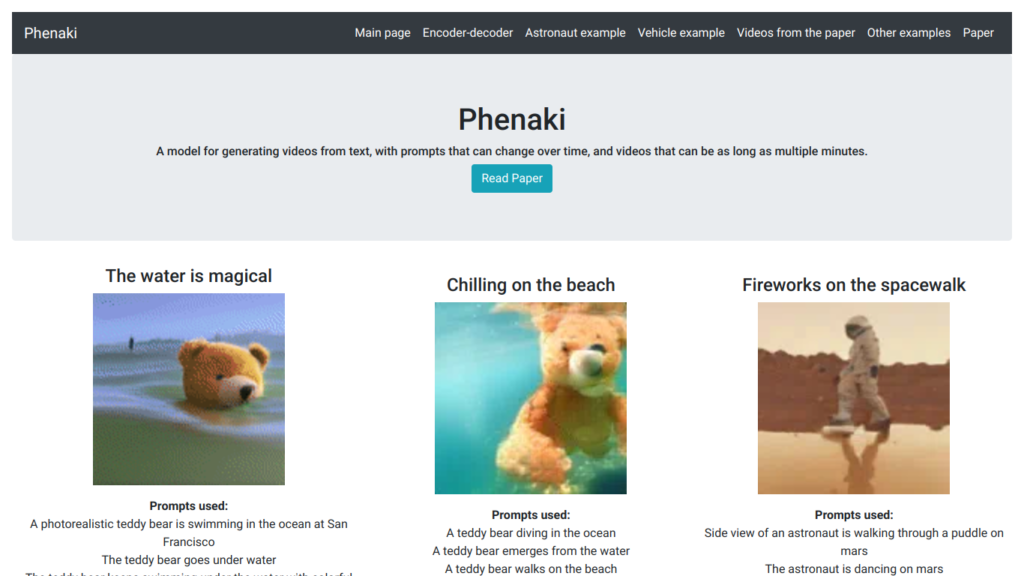
Phenaki generates videos from text prompts, offering the capability to create videos that can be multi-minute in length. By utilizing a bidirectional masked transformer and a causal model for learning video representation, Phenaki can compress videos into discrete tokens and generate realistic video sequences based on textual input. This model addresses challenges such as variable video lengths and limited high-quality text-video data by incorporating causal attention in time and joint training on image-text pairs.
The examples provided in the paper showcase the versatility of Phenaki, from generating videos of teddy bears swimming in the ocean to creating futuristic cityscapes with alien spaceships and lions in suits. The model’s ability to generate videos based on time-varying prompts sets it apart from previous video generation methods, allowing for storytelling and scene progression in an open-domain context.
Overall, Phenaki offers a new approach to video synthesis from text prompts, providing high-quality spatio-temporal output and surpassing per-frame baselines in the field. With its unique capabilities and focus on generating videos from time-varying prompts, Phenaki opens up new possibilities for creating dynamic and engaging video content.